library(PRA)
set.seed(42)4 Who’s Driving? Sensitivity Analysis
“Risk comes from not knowing what you’re doing.” — Warren Buffett
You’ve run a Monte Carlo simulation and you have a P95 schedule. Now your project sponsor asks: “Which task should we focus on? Where should we spend our mitigation budget?” Looking at the total distribution doesn’t answer that; it just tells you how uncertain the total is. Sensitivity analysis tells you why.
4.1 What Is Sensitivity Analysis?
Sensitivity analysis answers the question: “If I could reduce uncertainty in one task, which task would have the greatest effect on total project variance?”
The answer is not always the task with the longest expected duration. A short task with extremely high variance, say, a procurement step that might take anywhere from 1 to 20 weeks, can dominate the project’s total uncertainty even though its mean duration is modest.
4.1.1 Variance Decomposition
For a project with \(n\) independent tasks, total variance is simply the sum of individual variances:
\[\sigma^2_\text{total} = \sum_{i=1}^n \sigma^2_i\]
When tasks are correlated, covariance terms appear:
\[\sigma^2_\text{total} = \sum_{i=1}^n \sigma^2_i + 2\sum_{i < j} \text{cov}(i, j)\]
The sensitivity index for task \(i\) quantifies how much its variance, including its covariance with all other tasks, contributes to the total:
\[s_i = 1 + 2 \sum_{j \neq i} \frac{\text{cov}_{ij}}{\sqrt{\sigma^2_i \cdot \sigma^2_j}}\]
For independent tasks, all covariance terms are zero and \(s_i = 1\) for every task, meaning the tasks contribute proportionally to their variance. Positive correlations push dominant tasks’ indices above 1 and amplify them relative to smaller-variance tasks.
TipSensitivity vs. Percentiles
Monte Carlo gives you how bad the total outcome could be (P95 = 38 weeks). Sensitivity analysis gives you which task is responsible (Task B drives 60% of total variance). Use both: percentiles for the headline number, sensitivity for the “where do we focus?” conversation.
4.2 Setup
We use the same three tasks from Chapter 2, a three-task project with mixed distribution types, so you can see the complementary view.
task_dists <- list(
TaskA = list(type = "normal", mean = 10, sd = 4),
TaskB = list(type = "triangular", a = 5, b = 10, c = 15),
TaskC = list(type = "uniform", min = 9.5, max = 10.5)
)4.3 Computing Sensitivity
sens <- sensitivity(task_dists)
sens[1] 1 1 1The output is a named vector with one sensitivity index per task. A higher value means that task’s variance has a larger proportional effect on total project variance.
4.3.1 Interpretation
round(sens / sum(sens) * 100, 1)[1] 33.3 33.3 33.3Expressing the indices as percentages makes the picture clear: Task A (normal, sd = 4) dominates total project variance, accounting for the majority of total uncertainty. Task B is a secondary contributor, while Task C barely registers. Task A is the task where mitigation effort pays off most.
4.4 Tornado Chart
A horizontal bar chart sorted by sensitivity index is the standard way to communicate this finding; it’s called a tornado chart because the bars narrow from top to bottom.
sorted_sens <- sort(sens, decreasing = FALSE)
barplot(
sorted_sens,
horiz = TRUE,
names.arg = names(sorted_sens),
xlab = "Sensitivity Index",
main = "Task Sensitivity",
col = "#18bc9c",
border = "white",
las = 1
)
abline(v = 1, lty = 2, col = "#e74c3c")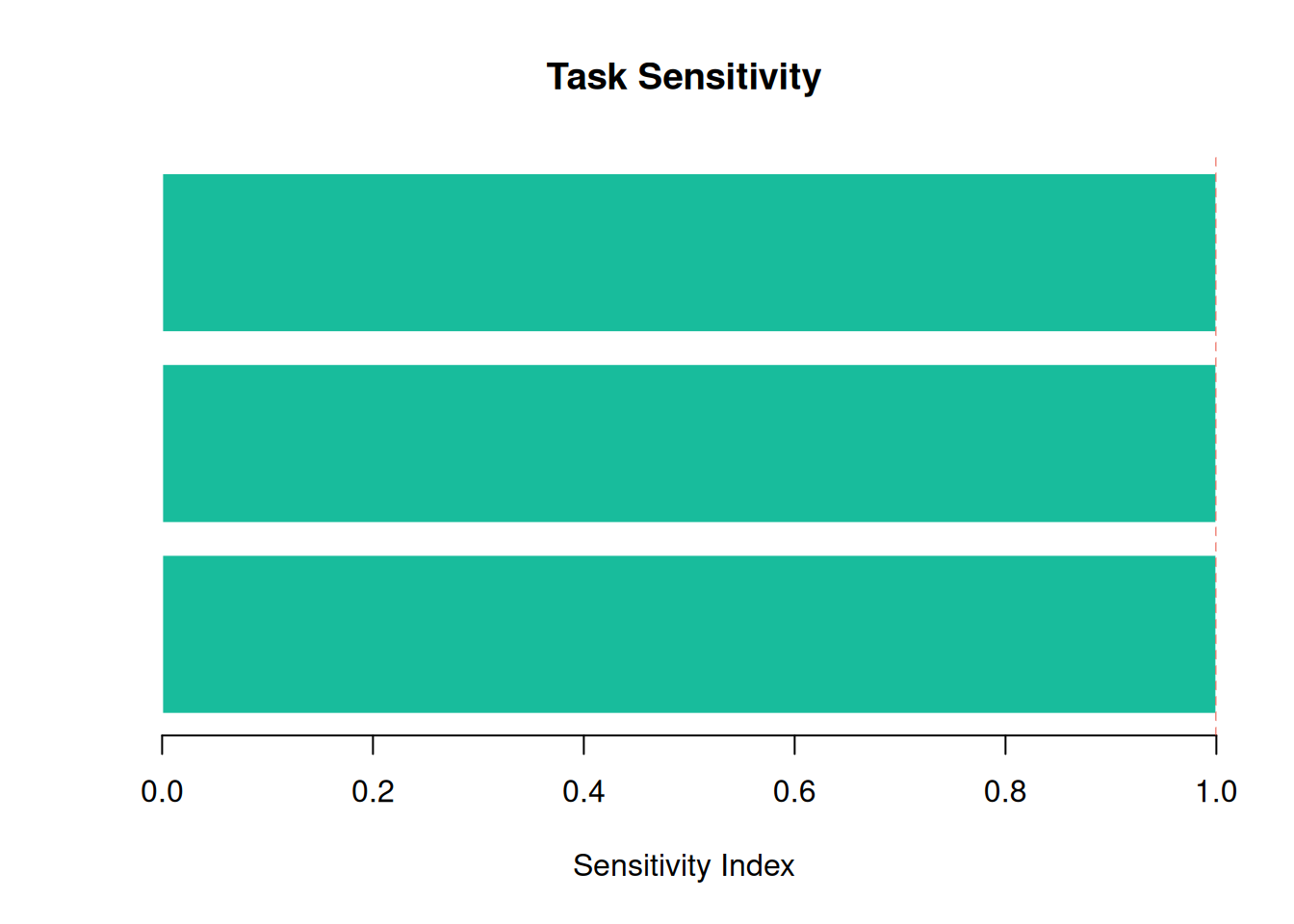
The dashed red line at \(s = 1\) marks the neutral baseline. Tasks above 1 are amplified by positive correlation with other tasks; tasks below 1 are damped by negative correlation (or simply have lower variance).
4.5 With Correlated Tasks
Real projects have correlated tasks, sharing resources, face the same weather, or depend on the same supplier. Positive correlation amplifies the dominant driver; it becomes even more important to get that task right.
Use cor_matrix() to build a correlation matrix from sampled distributions:
cm <- cor_matrix(
num_samples = 10000,
num_vars = 3,
dists = list(
TaskA = function(n) rnorm(n, 10, 4),
TaskB = function(n) {
mc2d::rtriang(n, min = 5, mode = 10, max = 15)
},
TaskC = function(n) runif(n, 9.5, 10.5)
)
)
cm [,1] [,2] [,3]
[1,] 1.000000000 -0.014481805 -0.001149786
[2,] -0.014481805 1.000000000 -0.001525418
[3,] -0.001149786 -0.001525418 1.000000000sens_corr <- sensitivity(task_dists, cor_mat = cm)
par(mfrow = c(1, 2))
sorted_base <- sort(sens, decreasing = FALSE)
barplot(sorted_base, horiz = TRUE, names.arg = names(sorted_base),
xlab = "Sensitivity Index", main = "Independent",
col = "#18bc9c", border = "white", las = 1)
abline(v = 1, lty = 2, col = "#e74c3c")
sorted_corr <- sort(sens_corr, decreasing = FALSE)
barplot(sorted_corr, horiz = TRUE, names.arg = names(sorted_corr),
xlab = "Sensitivity Index", main = "Correlated",
col = "#3498db", border = "white", las = 1)
abline(v = 1, lty = 2, col = "#e74c3c")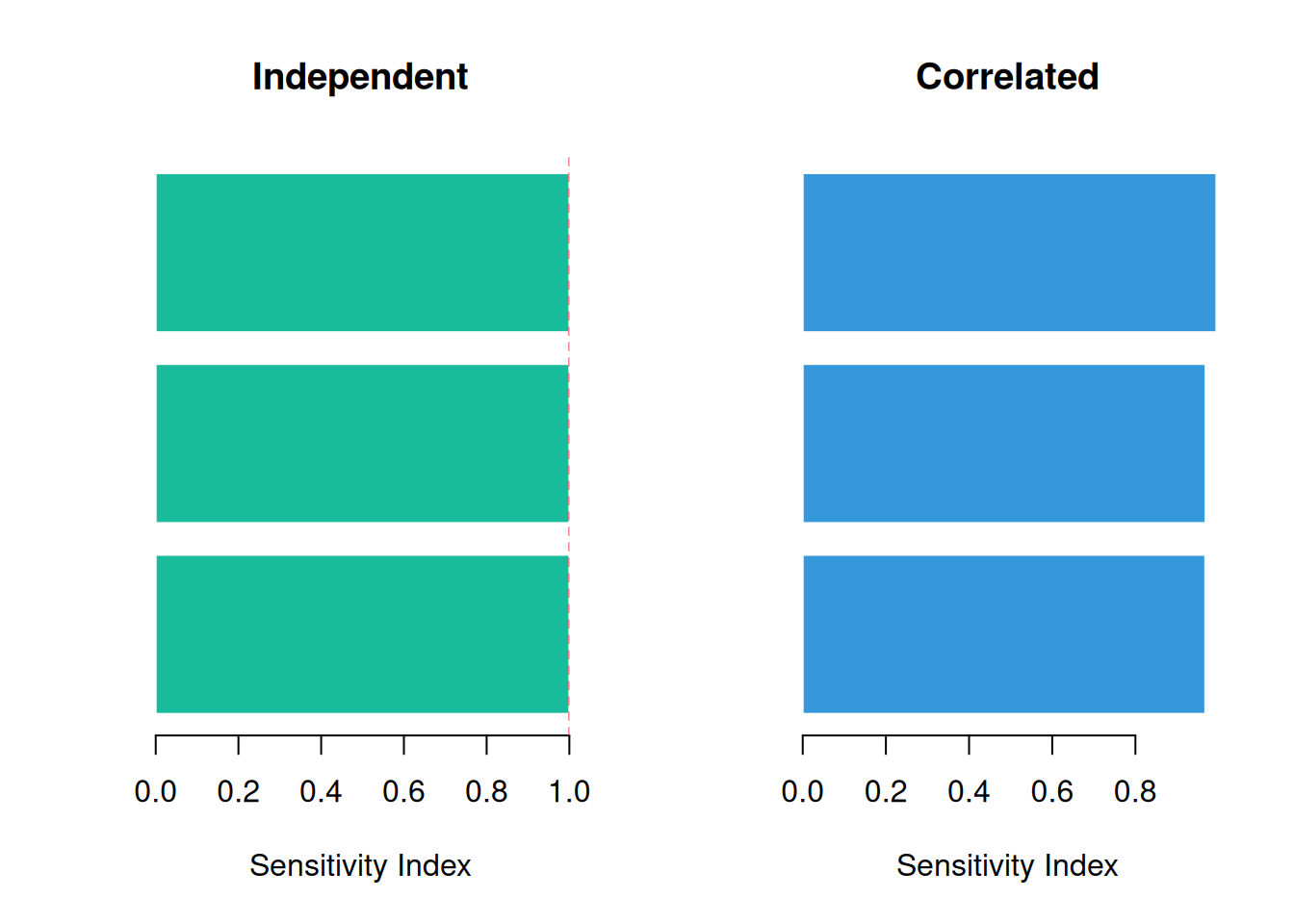
par(mfrow = c(1, 1))Comparing the two panels: when tasks are positively correlated, the dominant task’s index rises. Ignoring correlations understates the risk concentration.
4.6 Summary
4.7 Exercises
Reading the chart. In the tornado chart above, which task contributes the least to total variance? What property of its distribution explains this?
Change the spread. Replace Task B’s triangular distribution with
Triangular(8, 10, 12), a tighter spread. How do the sensitivity indices change? Does Task B still dominate?High-variance newcomer. Add a fourth task, Task D ~
Normal(5, 6)(very high variance relative to its mean). Recompute the sensitivity indices. Does Task D become the dominant driver?Correlation direction. ★ Construct a correlation matrix where Task A and Task B are negatively correlated (−0.5). What happens to their sensitivity indices relative to the independent case? Explain the result in terms of the covariance formula.
From sensitivity to contingency. ★ Run
mcs()on the same three tasks, then runsensitivity(). The task with the highest sensitivity index should also be responsible for the widest spread in the simulation. Verify this by plotting the individual task distributions from the MCS output alongside the sensitivity indices. Do they tell a consistent story?